蜕变测试(metamorphic testing)是一种新型软件测试技术。要把蜕变测试这个概念讲清楚,不是一件容易的事情。
蜕变测试的科学定义是:识别被测软件所具有的蜕变关系(metamorphic relations),通过检查这些蜕变关系是否成立来判断软件是否存在缺陷的技术。这里的蜕变关系,指的是被测软件多对输入/输出之间的某种关系。
显然,这个定义有点让人云里雾里。那么,有没有一种更通俗的解释呢?
如下图所示,在没有蜕变测试的时代,软件测试的原理是:给定输入,观察被测软件的输出,并与期望输出进行对比。基于对比结果判断软件是否存在缺陷。
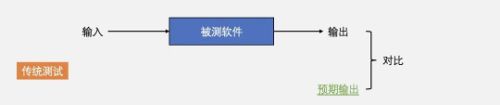
传统测试存在一个基本假设,那就是软件的期望输出是已知的。然而,许多情况下,软件的期望输出并不是已知的,或者说非常难知道。
例如,测试谷歌搜索引擎,输入关键词car,怎么判断搜索结果是对的?测试sin(x)计算函数,输入x=12,怎么判断计算结果(例如?0.5365)是对的?测试年龄-某疾病预测模型,输入年龄40,怎么判断模型返回的概率值(例如70.5%)是对的?
对于这些近乎“不可测”的场景,传统意义的软件测试技术爱莫能助,需要新的测试技术。于是,蜕变测试诞生了。如下图所示,蜕变测试的核心差异在于:
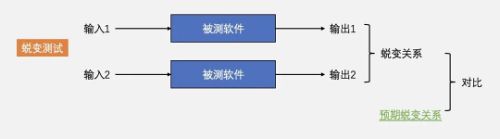
- 一次蜕变测试,包含的不是一次软件执行,而是多次软件执行;
- 我们观测的不再是单对输入/输出之间的关系,而是多对输入/输出之间的关系(蜕变关系);
- 我们对比的不是软件输出,而是软件的蜕变关系;
理解蜕变测试的关键,在于理解蜕变关系。然而蜕变关系是一个非常抽象的概念。在不同的应用场景和上下文中,蜕变关系的含义是不同的。
举个例子,如下图所示,在测试谷歌搜索引擎时,有两个用例,分别搜索关键词car和关键词autonomous car。这里隐含着一种蜕变关系:由于后者限定了输入关键词car的属性,因此后者的搜索结果应该是前者的一个子集。
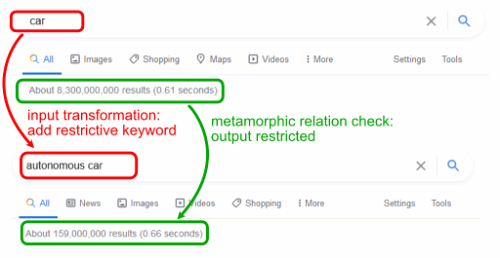
如果子集关系不成立,例如autonomous car的搜索结果数量大于car的搜索结果数量,或者autonomous car的搜索结果包含了一个不在car搜索结果范围内的结果,则说明子集蜕变关系没有成立,搜索程序可能存在缺陷。
那么,怎么进行蜕变测试呢?一般来说,蜕变测试主要包含四大步骤。
1、生成蜕变关系
如果说软件测试最难的是期望输出的生成,那么蜕变测试最难的就是蜕变关系的生成。生成蜕变关系没有一个标准套路,需要结合应用场景和上下文。
上面我们介绍的例子中,两次搜索结果是包含的关系。在搜索查询类应用中,蜕变关系还可以有以下类型:
等价关系:搜索大小为1MB的视频,搜索结果应该与搜索视频大小为1024KB的结果一样。
混排关系:搜索特定关键词,无论采用何种排序方式,搜索结果虽然顺序不同,但是结果的集合应该是相同的。
交集关系:搜索长度<5分钟视频与搜索长度>20分钟的视频,返回结果不应该存在任何交集。
并集关系:搜索任意关键字视频的结果,应该与三次搜索(长度<5分钟的视频/长度在5-20分钟的视频/长度>20分钟的视频)结果的并集相同。
蜕变关系的挖掘和生成,是蜕变测试研究的热点,也是蜕变测试应用的难点。
2、生成蜕变用例
蜕变测试包含多对输入/输出,因此蜕变测试用例包含多个测试用例。蜕变测试用例由两部分组成:起始测试用例(source test case)和跟随测试用例(follow up test case)。跟随测试用例由对起始测试用例的输入进行变换(根据蜕变关系)而得。
3、执行蜕变用例
4、校验蜕变关系
从应用角度来说,蜕变测试主要用在可测性不好的场景,例如机器学习系统、数据查询系统、科学计算系统、仿真与建模系统等。
需要注意的是,蜕变测试只是在一定程度上缓解软件的不可测性或者可测性不好的问题,而不能根本上解决这些问题。毕竟,蜕变关系只是被测软件众多属性中的一种。蜕变关系成立,不代表测试就进行得充分。
就像大师所言,软件测试只能证明软件存在缺陷,不能证明软件不存在缺陷。蜕变测试,更是如此。