摘要:一个系统的关键,需要更加高度可用。然而,这是非常困难的,假设不是不可能,去测量系统可能出故障的每种情况或预测将要多长时间才能恢复。但不要担心!这里仍然有许多测试策略可以用来了解系统的故障,减少宕机时间,并提高可用性。
软件不是一次性起作用,它要在所有时间都起作用或者接近这样。从20世纪50年代第一份带薪资的工作开始,就把可用性放在软件讨论中心进行了有效的管理。一个系统更关键是公司运行它,需要更加高度可用。在现代电子商务世界,即使几秒的宕机都可能导致一家公司亏损数百万美元的收入。
早期,企业尝试解决可用性问题投向了昂贵的解决方案,如多个冗余的计算机,配置多个电力供应,网络供应,以及磁盘阵列。这保证了一个服务器群中的任一个出现故障都不会使整个系统瘫痪。这些服务器被安装在地理位置相距遥远的数据中心,以便如任一数据中心瘫痪,另一个数据中心将继续保持运行。这些策略仍然在现代数据中心的设计上使用,然而行业在持续发展,包括云应用,containerization, autoscaling,以及分布式数据库管理系统。当硬件也不可避免地失败时,所有这些新技术同时在应用与底层硬件增加额外的可恢复层。
虽然业界对于提高系统故障恢复能力已经做了很多,可用性的概念还是非常多的被误解;可用性需求往往挥手或陈词滥调,难以衡量,通常被忽略。模糊的需求只在一定程度上有用,它们传达给测试人员需要进行某种测试,让系统与一个看似随机的可用性百分比进行比较。然而创建有用的可用性需求是很难做到的,在一个生产版本之前测量系统的实际可用性甚至更加困难,假设不是完全不可能。依我的经验,在测试阶段实在有太多的潜在因素需要衡量。我们所能做的,最好是尝试模拟一个系统可能出现故障的各种情况,并测量其从每个故障类型中的恢复能力。可能更准确的称这种级别的测试为恢复性测试,而不是可用性测试。
理解可恢复性和可用性
要更全面的了解可恢复性和可用性之间的差异,我们必须先看看系统可用性的一般公式:
Availability = mean time between failures / (mean time between failures + mean time to recover)
译:可用性=平均故障间隔时间/(平均故障间隔时间+平均故障恢复时间)
这个公式通常简写为:
可用性=MTBF(MTBF+MTTR)
所以,当我们说“恢复”,我们真正谈论的是MTTR,或者更具体的说,测量和减少MTTR。可用性,以另一种方式来解释整个方程,包括故障间隔时间以及故障恢复时间。牢记我们的小学数学,在这种情况下有两种办法提高商,可用性测试量——增加分子或减少分母。从这个意义上说,这个公式表明,如果想提高系统的可用性,既可通过减少系统可能出现故障情况的数量来提高MTBF,也可通过使系统(出现故障)能够快速恢复来降低MTTR。两点都做到特别有助于增加(系统)可用性。
获得更高的可用性意味着系统无障碍运行得更久(提高了MTBF),并且,当它出现故障,可以很快的恢复工作状态(降低了MTTR)。测量,报告,以及试图降低MTTR是恢复性测试的本质,当出现故障不清楚系统如何恢复,是不可能预测系统的可用性的。
可用性测试
在首次发布之前,试图直接测试可用性存在两大难题。首先是,测试系统可能失败的所有情况是不切实际的。软件系统是多层级和非常复杂的,不可能预测和模拟系统可能出现故障的每一种情况。然而,正规的流程如,故障模型和影响分析(FMEA)和故障树分析(FTA)可以用来了解系统可能出现故障的许多情况,也可帮助团队优先考虑这些最有可能发生的或最有(危害)影响的故障。
如果你的组织对完全规范化的FMEA或FTA应用没有做好十足准备,你的QA团队仍然能够找出更有可能和更有影响的故障类型,通过向开发人员和架构师问几个关键问题:
- 你预料系统出现故障的情况有哪些?
- 如果系统断电将会发生什么?是另一个(冗余系统)按预期的接管吗?
- 如其中一台机器出现网络故障将会发生什么?应用程序将按预料怎样响应?
- 当数据库崩溃会发生什么?
- 当发布新版本代码到生产环境,必须要重启应用服务器吗?
关于系统可能怎样出现故障,这里有许多乃至更多的问题需要询问。但这里的关键是让谈话继续下去,以及鼓励团队思考故障和怎样开发系统才能优雅的处理掉故障。从测试人员的角度来看,这些问题可以让测试员不把精力放在系统能提供多少可用性上,而是把精力放在有多少种(故障)情况上,作为测试员,可以在系统模拟宕机。
试图测试系统可用性的第二个困难是,方程组成部分中的(故障)平均恢复时间往往含有人为和流程因素,在系统转入生产环境之前是很难预测的。例如,如果一个生产数据库崩溃,需要重启数据库让系统恢复到正常状态:如果恢复是自动的,解决这个问题也就几秒钟(MTTR)的事;如果现场管理员需要执行重启,在迅速警觉情况下可能要几分钟;如果管理员正在睡觉,必须要通过手机提醒,可能就要几小时了。
为了准确预测我们组织对出现故障的响应,在相同情况下,预计在生产环境下最坏的可能时间下使系统出现故障。这可能包括我们的测试系统在深夜出现故障,提醒我们的通宵支持团队,假设一个生产环境紧急情况发生在凌晨3点让管理员解决问题。大多数组织不支持生死系统(life-or-die system),这种级别的测试根本不会发生,所以在(系统)搬到生产环境之前使得可用性测量不可能。
这里的关键是没有成本和精力在预生产环境直接测试,企业往往也不愿意或不能支持产品预发布。这些活动通常更多在于生产环境的各种准备而不在测试,并不总是(但可以)由测试团队驱动。然而,作为项目团队的一员,如果你听到周围发生的“高可用性”的对话,而没有听到关于生产准备,这可能意味着你有机会帮助你的团队更好地理解停机时间和可用性是怎样直接相关的。
减少宕机时间和增加可用性
很多人都不知道,短短几分钟宕机时间可能对系统可用性有着怎样的影响。
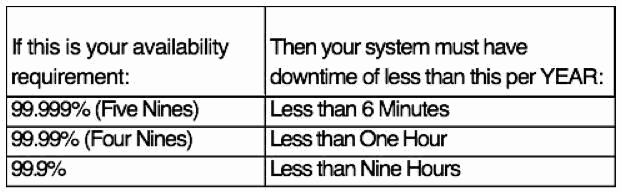
宕机时间怎样影响系统可用性。
正如你所看到的,当可用性需求提高时,系统宕机的数量显著下降。可用性目标越高,团队越积极的去检测系统出现故障的可能原因,或消除它们,构建冗余或自动恢复。
越来越多的软件系统正在开发支持一定程度的自动恢复(功能)。意图减少恢复时间到仅几秒,或者,可能性地,降低到0。如果高可用性重要和自动恢复正常(功能)内置于系统中,有必要让人测试这些功能。
从不断出现故障开始
如果不能测试系统可能出现故障的每种情况,就不能准确地预测在每一种情况下的恢复时间,希望都失去了?当然不是!事实上,测试团队可以直接对提高系统的MTBF做出贡献,或者在某些情况下,降低MTTR。这两种类型的测试可以分为破坏性测试和恢复性测试,通常(但不一定)一起执行。
故障测试的目标是通过减少系统可能出现故障的情况来提高MTBF。
恢复性测试的目标是通过减少系统从出现故障到恢复的时间来降低MTTR。
作为真实的功能测试,这是完全可能,事实上,需要尽可能多的对故障和恢复性测试自动化。虽然你能对已确定的故障类型测试,如网络或停电,通过在测试实验室简单的拔出电缆,但自动化提高了过程可重复性水平,在长期的项目中变得非常重要。自动化这些测试是,一次测试和每次构建和发布都要测试的区别。
这里的秘诀,从Netflix公司了解到关于故障测试经验教训,“避免故障的最好方法是不断地出现故障”。关键是不必要从从不做故障测试到总是做故障测试,而是组织可以同意走向该模式的步骤。
如果你正好没事情做,那就做些事。即使是一个简单如拔出网络电缆的测试,明白应用是如何响应的第一步,了解故障以及你的系统恢复特性。
由“51ste软件测试部落”ruink 译自 Andrei Sandu 《Testing Strategies to Increase System Availability 》一文。