从应用系统上线那一刻开始,随着用户量的增加、业务功能的持续迭代,系统会面临各种不同程度的挑战,如果不及时采取优化措施,我们会发现诸多问题,比如:系统怎么越来越慢了,流量一高系统就卡顿、甚至宕机等等。
1、性能衡量指标
在衡量系统性能基线时,一般会从“响应时间”和“并发能力”两个维度考虑。
1)响应时间(RT)
响应时间通常为应用系统从请求发出开始到客户端收到响应所消耗的时间。常以“平均响应时间”、“百分位数”等指标来衡量。
平均响应时间
该指标反映的是系统对某一请求的平均处理能力,计算方式是:某请求响应时间之和 ÷ 该请求总的请求次数。举个例子:某接口总共发起了8次请求,其中有1次3ms,3次5ms,4次6ms,那么此接口的平均响应时间就是 (1 * 3 + 3 * 5 + 4 * 6) / 8 = 5.25ms 。
百分位数(Top Percentile)
一种统计学术语,反映的是超过n%的请求都在m时间内返回。一般用TPn=m来描述,比如:TP99=5ms,表示超过99%的请求都能在5ms内返回。它的计算方式是:将接口的响应时间按从小到大的顺序进行排列,取特定百分位的耗时,即为该接口的百分位数。举个例子:接口A总共发起了100次请求,响应时间依次是1ms、2ms、3ms、...、100ms,那么TP95就是95ms。
一般而言,百分位数更能反映请求的整体响应情况,因为在高并发场景中,常常会出现一些长尾请求,如果采用平均响应时间去衡量,由于长尾请求会被大量低RT平均掉,进而无法及时感知真实业务状况。举个例子:某接口有100次请求,其中97次1ms,3次100ms,平均响应时间为 (1 * 97 + 3 * 100) / 100 = 3.97ms,此时3.97ms并不能真实反映接口的整体性能,因为其中97次请求RT才1ms。
长尾请求 一般是指明显高于均值的那部分占比较小的请求。业界关于延迟有一个常用的P99标准,也就是99%的请求延迟要满足在一定耗时以内,1%的请求会大于这个耗时,而这1%就可以认为是长尾请求。共享资源竞争,周期性的垃圾回收,运维活动(比如日志备份), 硬件或者软件故障,网络的抖动等等,都有可能造成长尾请求。
2)并发能力
并发能力一般用QPS或TPS来衡量。QPS指的是每秒请求数,TPS是指每秒事务数。一般在做性能评估时,TPS用的比较多。
2、性能优化本质
在算法领域,评价一个算法的效率如何,主要看它的时间复杂度和空间复杂度情况。同理,如果将“响应时间”比作时间维度的话,“并发能力”可类比为空间维度。那么,在做性能优化时,本质上也是从“优化时间”、“优化空间”、“时空互换”三个方向去思考,然后在空间、时间上不停地做取舍。
举一个生活中的例子来说明下。一条长度为5km的道路,道路的限速是50km/h,同时,规定在任何时刻,车道上有且仅有一辆汽车。那么,在1h内,从A点出发到达B点的汽车最多只有10辆。假设上级部门想提升这块路段的车流量,我们该怎么办?

第一种方式,可以增加车道数(空间维度):将道路从单车道变为多车道,比如增加到6车道,那么,在1h内,从A点出发到达B点的汽车数可提量到60辆,见图:
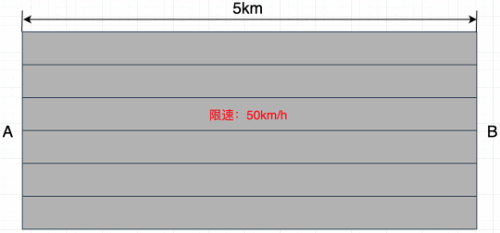
第二种方式,道路提速(时间维度):将道路限速从50km/h提升到100km/h,那么在1h内,从A点出发到达B点的汽车数可提量到20辆,见图:
实际应用系统的优化策略比道路提升车流量的策略要复杂的多,在后续文章中笔者会列举出一些常见的优化策略。