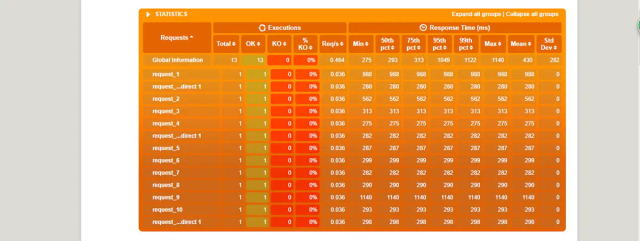
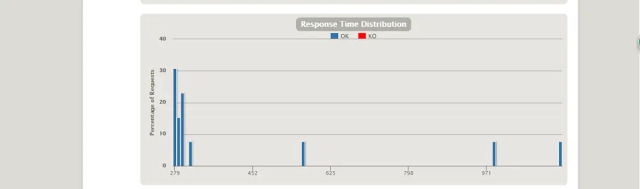
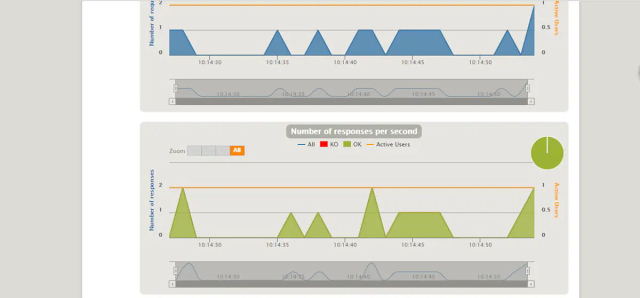
要针对gatling的report进行详尽透彻的分析,并正确评价系统,甚至找出性能瓶颈。
HAR文件生成脚本
上面讲到HTTP代理模式存在安全隐患,会存在浏览器不支持的情况,所以不建议使用。使用HAR文件转换就不存在这个问题了,且这样产生的脚本会更加精准。
Gatling的Recorder提供了HAR Converter的功能。
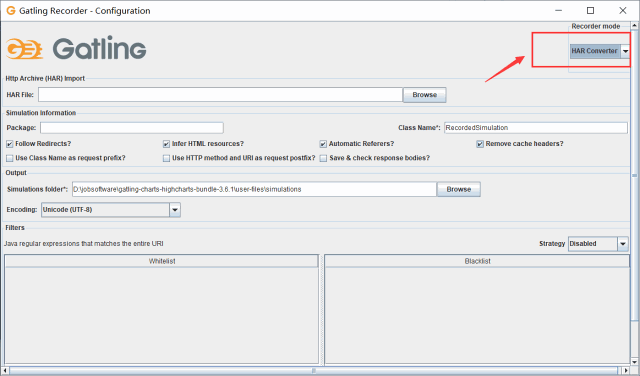
什么是HAR文件呢?
维基百科解释:The HTTP Archive format, or HAR, is a JSON-formatted archive file format for logging of a web browser’s interaction with a site。简单理解就是记录浏览器请求的日志的文件。
怎么获取HAR文件呢?一是可以通过Chrome的开发者工具获取,二可以通过一些软件获取,比如fiddler、Charles proxy等。这里我们使用Chrome来获取。
步骤
1、使用Chrome浏览器访问网站,打开开发者工具(更多工具–>开发者工具/F12),清除已有request信息,勾选Preserve log(保留录制期间的所有log信息)
2、网页操作:xxxxxx(省略)。
3、点击停止记录日志后,将日志存为HAR文件。
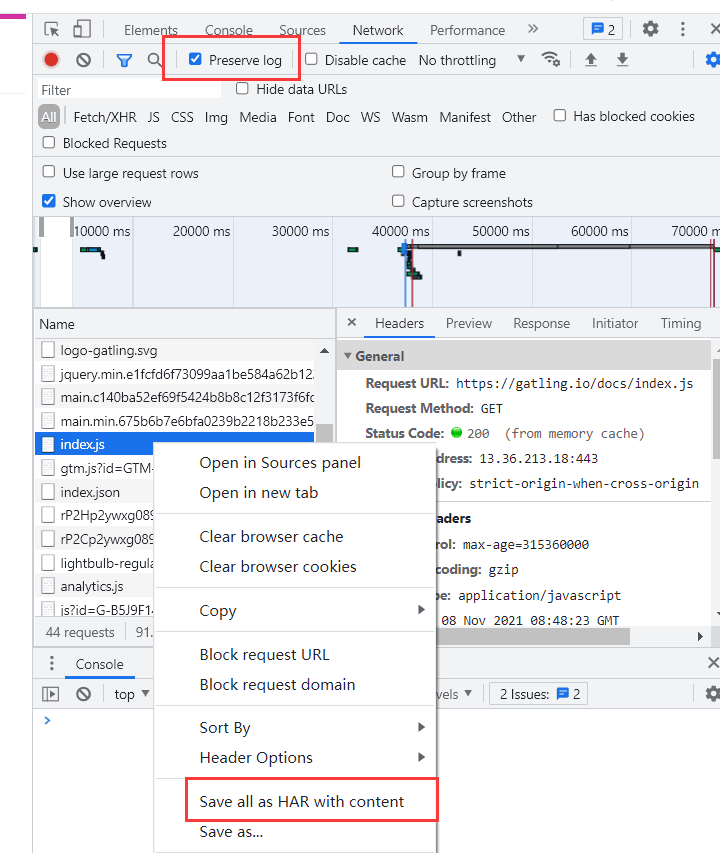
4、配置recorder。
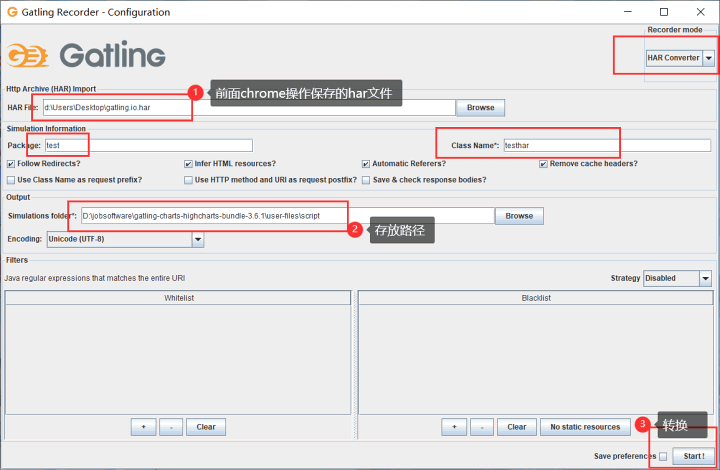
5、点击start,转换成功后可在项目路径看到scala脚本了。

高级用法
分层设计
类似于Selenium的PageObject模式。
借用官网解释
在我们的场景中,有三个独立的过程
- 搜索:按名称搜索模型
- 浏览:浏览模型列表
- 编辑:编辑给定的模型
将提取这些链并将它们存储到对象中,对象是原生的Scala单例。
object Search {
val search = exec(http("Home") // let's give proper names, as they are displayed in the reports
.get("/"))
.pause(7)
.exec(http("Search")
.get("/computers?f=macbook"))
.pause(2)
.exec(http("Select")
.get("/computers/6"))
.pause(3)
}
object Browse {
val browse = ???
}
object Edit {
val edit = ???
}
和Java就很相似了,借用面对对象的思想,把公用的封装为对象,需要使用的时候就调用对象里面的方法。
可以使用这些可重用的业务流程重写我们的场景
val scn = scenario("Scenario Name").exec(Search.search, Browse.browse, Edit.edit)
更多用法参见官网:https://gatling.io/docs/current/general/
- Virtual User:其他一些工具(如JMeter)将这些虚拟用户实现为线程。Gatling 将它们实现为消息,这样可以更好地扩展并且可以轻松处理数千个并发用户。
- Scenario:如何设计、编写场景。
- Simulation:模拟器,如何模拟虚拟用户。
- Session:沿场景工作流传递的消息,根据虚拟用户特定数据使您的场景步骤动态化(避免受缓存影响)。
- Feeders:供测试人员将来自外部源的数据注入到虚拟用户的会话中。
- Checks:检查点用法。(即执行每步骤设置检查点,判定该步骤是否执行成功)
- Assertions:断言 API 用于验证全局统计数据(例如响应时间或失败请求的数量)是否与整个模拟的预期相符。(即用于判断性能测试是否达到预期目标)
- Reports:Gatling的报告配置及各报告的图标、指标说明。