所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
消费端处理消息的业务逻辑保持幂等性。只要保持幂等性,不管来多少条重复消息,最后处理的结果都一样。保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现。利用一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。
消息的丢失问题
每个MQ组件都有自己的方案,由于篇幅有限,我就简单聊聊RocketMq(互联网项目常用的Mq技术,经历过阿里双十一高并发的考验)防丢失方案吧。
一般RocketMq会有以下几种场景丢失消息:
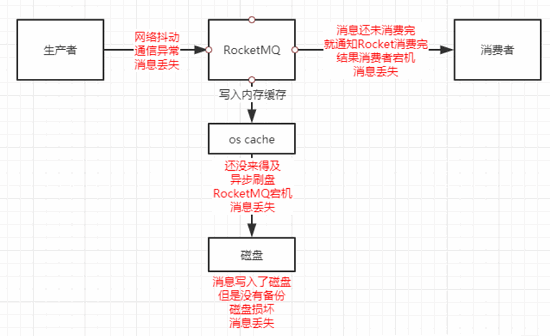
1、生产者将消息发送给Rocket MQ的时候,如果出现了网络抖动或者通信异常等问题,消息就有可能会丢失。
2、消息需要持久化到磁盘中,这时会有两种情况导致消息丢失:
① RocketMQ为了减少磁盘的IO,会先将消息写入到os cache中,而不是直接写入到磁盘中,消费者从os cache中获取消息类似于直接从内存中获取消息,速度更快,过一段时间会由os线程异步的将消息刷入磁盘中,此时才算真正完成了消息的持久化。在这个过程中,如果消息还没有完成异步刷盘,RocketMQ中的Broker宕机的话,就会导致消息丢失
② 如果消息已经被刷入了磁盘中,但是数据没有做任何备份,一旦磁盘损坏,那么消息也会丢失。
3、消费者成功从RocketMQ中获取到了消息,还没有将消息完全消费完的时候,就通知RocketMQ我已经将消息消费了,然后消费者宕机,但是RocketMQ认为消费者已经成功消费了数据,所以数据依旧丢失了。
那么如何保证消息的零丢失呢?

1、生产者保证消息不丢失的方案是使用RocketMQ自带的事务机制来发送消息,大致流程为:
① 首先生产者发送half消息到RocketMQ中,此时消费者是无法消费half消息的,若half消息就发送失败了,则执行相应的回滚逻辑。
② half消息发送成功之后,且RocketMQ返回成功响应,则执行生产者的核心链路。
③ 如果生产者自己的核心链路执行失败,则回滚,并通知RocketMQ删除half消息。
④ 如果生产者的核心链路执行成功,则通知RocketMQ commit half消息,让消费者可以消费这条数据。
在使用了RocketMQ事务将生产者的消息成功发送给RocketMQ,就可以保证在这个阶段消息不会丢失。
消息中间件要保证消息不丢失,首先需要将os cache的异步刷盘策略改为同步刷盘,这一步需要修改Broker的配置文件,将flushDiskType改为SYNC_FLUSH同步刷盘策略,默认的是ASYNC_FLUSH异步刷盘。一旦同步刷盘返回成功,那么就一定保证消息已经持久化到磁盘中了;为了保证磁盘损坏不会丢失数据,我们需要对RocketMQ采用主从机构,集群部署,Leader中的数据在多个Follower中都存有备份,防止单点故障。
消费者如何保证不丢失消息呢?消息到达了消费者,RocketMQ在代码中就能保证消息不会丢失。
//注册消息监听器处理消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List msgs, ConsumeConcurrentlyContext context){
//对消息进行处理
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
上面这段代码中,RocketMQ在消费者中注册了一个监听器,当消费者获取到了消息,就会去回调这个监听器函数,去处理里面的消息。
当你的消息处理完毕之后,才会返回 ConsumeConcurrentlyStatus.CONSUME_SUCCESS
只有返回了CONSUME_SUCCESS,消费者才会告诉RocketMQ我已经消费完了,此时如果消费者宕机,消息已经处理完了,也就不会丢失消息了。
如果消费者还没有返回CONSUME_SUCCESS时就宕机了,那么RocketMQ就会认为你这个消费者节点挂掉了,会自动故障转移,将消息交给消费者组的其他消费者去消费这个消息,保证消息不会丢失。
使用上面一整套的方案就可以在使用RocketMQ时保证消息零丢失,但是性能和吞吐量也将大幅下降。
使用事务机制传输消息,会比普通的消息传输多出很多步骤,耗费性能。
同步刷盘相比异步刷盘,一个是存储在磁盘中,一个存储在内存中,速度完全不是一个数量级,主从架构的话,需要Leader将数据同步给Follower,消费时无法异步消费,只能等待消费完成再通知RocketMQ消费完成。
消息零丢失是一把双刃剑,要想用好,还是要视具体的业务场景而定,选择合适的方案才是最好的。
怎么测试Mq的组件?
最后一点特别关键,也是很多面试官爱问的面试题,你怎么测试mq组件的?主要分为以下几个方面:
Mq异常测试
1、消息重复发送
消息重复发送,幂等性测试。(什么是幂等测试,可阅读“什么是接口的幂等性测试?”)
2、消息到达顺序不一致
消息到达顺序不一致,导致业务异常。
比如:订单下单后再取消,如果先收到取消的消息,再收到下单消息,就会有问题。
3、消费失败,生产者、消费者重试机制
4、Mq性能测试
线上即将投入使用的Mq集群,通常都会做个性能摸底,在Mq的TPS和机器的资源使用率之间取得一个平衡。
举个例子,mq在资源利用率极高的情况下可以到10万TPS,但是机器的内存、cpu、io负载特别高,濒临宕机,这个是极其不安全的,可是当TPS在8万的时候,机器的内存、cpu、io负载较高,但是还在可接受范围内,这批机器就比较安全,不至于宕机。
所以我们的目标就是综合TPS和机器负载,尽量找到一个最好的TPS,并且机器各项负载都在可接受范围内,这才是我们的测试目的。为此要性能压测要进行以下几个步骤:
1、代码中创建几个生产者,投递消息
我们可以在代码里让两个生产者,不停的往集群中发送消息,每个生成者启动多个80个线程(具体参考服务器配置),相当于每台机器有80个线程并发往Mq集群发送消息。每条消息的大小固定。
2、实时查看集群中服务器的cpu、内存负载情况、磁盘io、JVM GC频率、网卡流量等。
可以使用命令,也可以使用监控软件prometheus 等监控服务器设备的负载。
3、当设备负载任何一个指标已经超过安全阈值以后,立即查看Mq管理页面的TPS峰值,譬如机器网卡是128M,网卡实际流量有100M,接近千兆网流量,我们mq的TPS峰值是7万左右,我们就认为7万TPS是新集群最佳TPS.