- 要处理好缓存数据全部丢失后,如何能快速把数据重新加载到缓存中。
- 缓存数据的分布式冗余备份,当出现数据丢失时,可以迅速切换使用备份数据。
2、同步转异步推送
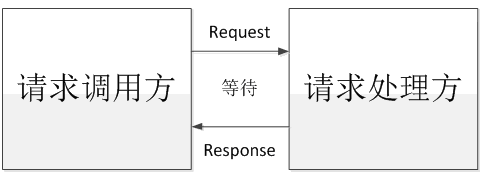
同步:指的是系统收到一个请求后,在该请求没有处理完成时,就一直不返回响应结果,直到处理完成了才返回响应结果。如下图所示:
异步:与同步相比,异步指的是系统收到一个请求后,只立即返回请求调用方请求接收成功,在请求处理完成后,再异步推送处理结果给调用方,或者请求调用方在间隔一定时间再重新来获取请求结果。如下图所示:
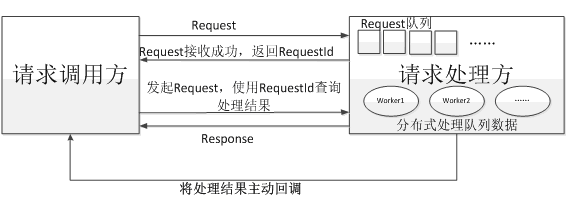
同步转异步主要是解决同步请求时的阻塞等待,一直处于阻塞等待的请求,往往会造成连接不能快速释放,从而导致高并发处理时,连接数不够用,通过队列异步接收请求后,请求处理方再进行分布式的并行处理,从而达到处理能力扩展,并且网络连接也可以快速释放。
3、拆分
拆分 指的是将系统中的复杂的业务调用拆分为多个简单的调用,一般遵循的原则如下:
- 对于高并发的业务请求调用都单独拆分为单个的子系统应用。
- 对于并发访问量接近的业务,可以按照产品业务进行拆分,相同的产品业务都归类到一个新的子系统中。
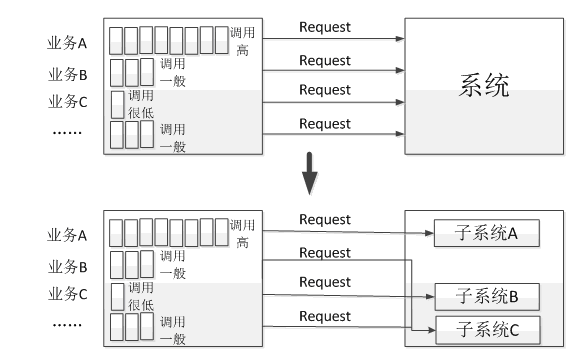
系统拆分带来的好处就是高并发的业务不会对低并发业务的性能造成影响,而且系统在硬件扩展时,也可以有针对性的进行扩展,避免资源的浪费。
4、任务分解与并行计算
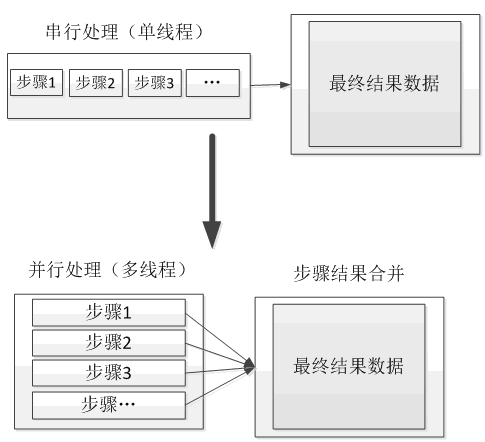
任务分解与并行计算指的是将一个任务拆分为多个子任务,然后将多个子任务并行进行计算处理,最后只需要再将并行计算的结果合并在一起返回即可。目的是通过并行计算的方式来增加处理性能。
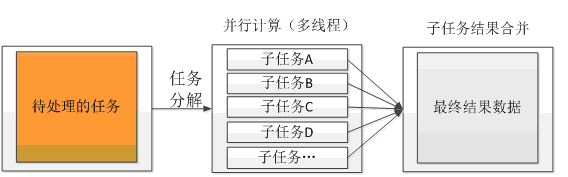
另外对于包含多个处理步骤的串行任务,也可以尽量按照如下图所示的方式转换为并行计算处理。
5、索引与分库分表
索引
指应用程序在查询时,尽量走数据库索引查询,数据库表在创建时也尽量对查询条件的字段建立合适的索引,这里强调一定是合适的索引,如果索引建立不合适,不仅对查询效率没有任何的帮助,反而会使数据库表在插入数据时变的更慢,因为一旦建立了索引后,数据在插入时,索引也会自动更新,这样就加大数据库的插入时的资源消耗。
分库
一般指的是一个数据库的存储已经很大了,查询和插入时I/O消耗非常大,此时就需要将数据库拆分成2个库来减轻读写时I/O的压力。
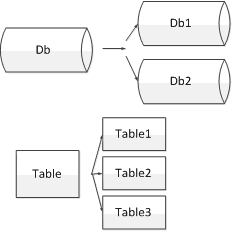
常见的分库分表方式如下:
- 按照冷热数据分离的方式:一般将使用频率非常高的数据称之为热数据,查询频率较低或者几乎不被查询的数据称之为冷数据,冷热数据分离后,热数据单独存储,这样数据量就会下降下来了,查询的性能自然也就提升了,而且还可以更方便的单独针对热数据做I/O的性能调优了。
- 按照时间维度的方式:比如可以按照实时数据和历史数据分库分表,也可以按照年份、月份等事件区间进行分库分表,目的是尽可能的减少库表中的数据量。
- 按照一定的算法计算的方式:此种方式一般适用于数据都是热数据的情况,比如数据无法做冷热分离,所有的数据都经常被查询,而且数据量又非常的大。此时就可以根据数据中的某个字段做算法计算(注意的是这个字段一般是数据查询时的检索条件字段),使得数据能均匀的落到不同的分表中去,查询时再根据查询条件字段做算法计算就可以快速的定位到是需要到哪个表中去进行查询。
数据分库分表后,带来的另一个好处就是,如果单次查询时,需要查询多个分表,那么此时就可以通过多线程并行的方式去查询每个分表,最后对每个分表的查询结果做一次合并即可,这样也可以使得查询的效率更高。
测试新兵(2023-06-29 07:33:59)
写的太好了,非常实用,已经收藏~