HttpRunner 简介
HttpRunner 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。目前已经发布了 HttpRunner 2.x 版本。
GitHub 地址:https://github.com/HttpRunner/HttpRunner
核心特性
- 继承 Requests 的全部特性,轻松实现 HTTP(S) 的各种测试需求
- 采用 YAML/JSON 的形式描述测试场景,保障测试用例描述的统一性和可维护性
- 借助辅助函数(debugtalk.py),在测试脚本中轻松实现复杂的动态计算逻辑
- 支持完善的测试用例分层机制,充分实现测试用例的复用
- 测试前后支持完善的 hook 机制
- 响应结果支持丰富的校验机制
- 基于 HAR 实现接口录制和用例生成功能(har2case)
- 结合 Locust 框架,无需额外的工作即可实现分布式性能测试
- 执行方式采用 CLI 调用,可与 Jenkins 等持续集成工具完美结合
- 测试结果统计报告简洁清晰,附带详尽统计信息和日志记录
- 极强的可扩展性,轻松实现二次开发和 Web 平台化
设计理念
- 充分复用优秀的开源项目,不追求重复造轮子,而是将强大的轮子组装成战车
- 遵循 约定大于配置 的准则,在框架功能中融入自动化测试最佳工程实践
- 追求投入产出比,一份投入即可实现多种测试需求
HttpRunner 的测试用例分层机制 (适用于 2.X)
背景描述
HttpRunner 从 2.0 版本开始,对测试用例组织形式进行了较大的调整,更正了之前在自动化测试概念上的偏差。
对应地,测试用例分层机制也进行了重新设计,因此在概念和使用方法方面都会出现很大的差异。本文便是对新的测试用例分层机制进行介绍。
测试用例分层模型
虽然使用方法变化了,但原理上都是相同的。
概括来说,测试用例分层机制的核心是将接口定义、测试步骤、测试用例、测试场景进行分离,单独进行描述和维护,从而尽可能地减少自动化测试用例的维护成本。
逻辑关系图如下所示:
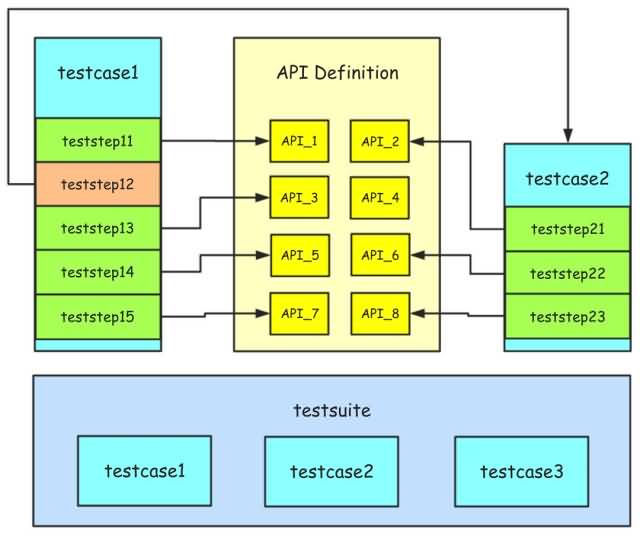
同时,强调如下几点核心概念:
- 测试用例(testcase)应该是完整且独立的,每条测试用例应该是都可以独立运行的
- 测试用例(teststep)是测试步骤的 有序 集合,每一个测试步骤对应一个 API 的请求描述
- 测试用例集(testsuite)是测试用例的 无序 集合,集合中的测试用例应该都是相互独立,不存在先后依赖关系的;如果确实存在先后依赖关系,那就需要在测试用例中完成依赖的处理
如果对于上述第三点感觉难以理解,不妨看下上图中的示例:
- testcase1 依赖于 testcase2,那么就可以在测试步骤(teststep12)中对 testcase2 进行引用,然后 testcase1 就是完整且可独立运行的;
- 在 testsuite 中,testcase1 与 testcase2 相互独立,运行顺序就不再有先后依赖关系了。
分层描述详解
理解了测试用例分层模型,接下来我们再来看下在分层模型下,接口、测试用例、测试用例集的描述形式。
接口定义(API)
为了更好地对接口描述进行管理,推荐使用独立的文件对接口描述进行存储,即每个文件对应一个接口描述。
接口定义描述的主要内容包括:name、variables、request、base_url、validate 等,形式如下:
name: get headers
base_url: http://httpbin.org
variables:
expected_status_code: 200
request:
url: /headers
method: GET
validate:
- eq: ["status_code", $expected_status_code]
- eq: [content.headers.Host, "httpbin.org"]
其中,name 和 request 部分是必须的,request 中的描述形式与 requests.request 完全相同。
另外,API 描述需要尽量保持完整,做到可以单独运行。如果在接口描述中存在变量引用的情况,可在 variables 中对参数进行定义。通过这种方式,可以很好地实现单个接口的调试。