CPU饱和了很好判断,CPU利用率=100%或者接近100%就是指标。内存饱和了也很好判断,内存用光了之后持续读写swap(或者叫pagingspace)就是指标,网络IO有没有饱和看带宽利用率这个指标。那么,作为4大资源之一的磁盘IO,怎么判断是否饱和了呢?因为很多时候磁盘繁忙程度diskbusy(或者叫利用率util,或者叫活动时间)=100%的时候,系统吞吐量还可以继续增加。
存储IO的三大性能指标
首先,我们复习一下,存储IO能力的三大性能指标:IOPS、MBPS、响应时间。
这里面压根就没有diskbusy。也就是说,判断存储IO能力是通过三个指标判断的,并不是这个叫做diskbusy(or util,or活动时间)的单一指标来判断的。
那么我们为什么还要讲这个指标呢?因为通过三大指标来判断是不是IO能力饱和实在是不可能的。
因为,IO能力的三大指标是因读写模型的不同而不同(读写模型是指:读写比例,顺序读写or随机读写,读写size等等),你并不知道三大指标的某个数值组合是不是饱和状态,因为一般不会针对这个存储做专项的测试。用户甚至不知道自己的读写模型是什么样的,这就更谈不上专门测存储了。
磁盘繁忙程度
那么,这种情况下,怎么判断存储IO是否饱和呢?这就有了这个不靠谱的指标diskbusy(or util,or活动时间)
这个指标的官方描述:以linux系统为例
%util
Percentage of elapsed time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100% for devices serving requests serially. But for devices serving requests in parallel, such as RAID arrays and modern SSDs, this number does not reflect their performance limits.
译:向设备发出I/O请求所用的时间占总时间的百分比(设备的带宽利用率)。当此值对于串行提供请求的设备接近 100% 时,会发生设备饱和。但对于并行服务请求的设备,如RAID阵列和现代SSD,这个数字并不反映它们的性能限制。
我用通俗的语言解释一下,util是磁盘驱动的繁忙程度。
打个比方,如果一条马路上单位时间内可以通过100辆车,我们把这个极限值定义为util=100%,那么如果单位时间内只有1辆车,util就=1%。
但每辆车上坐的人数是不确定的。同样是util=100%:
1)每辆车坐一个人,车道的运输能力就是100人/单位时间。
2)每辆车坐10个人,车道的运输能力就是1000人/单位时间。(比如10个请求或报文在一个block中被写下去,比如写日志对buffer更改十次再刷入磁盘)
另外,后来存储设备发展出array和ssd之后,马路就不止一个车道了,出现了多个车道。util仍然是按照单车道计算的。即使是util=100%,仍然可以在单位时间内通过更多的车,因为增加了车道。
我这个例子不是很贴切,磁盘的util其实是车道被占用的时间百分比,还和读写模型有关(顺序读写vs随机读写,读写比例,读写size等都会影响),对应咱们这个例子,就是有大车,有小车,有快车,有慢车。
为了让问题简单化,我们抛开多个车道的情况不管,只看单车道的情况下,什么样的情况会造成这种问题。
举例1
我们的一个系统TPS从100~500的这么大的跨度中,util始终是100%左右。原因就是block落盘的过程中,低TPS一个block写入的业务少,高TPS一个block写入的业务多。具体是怎么造成的呢?
如果出现下面两幅图的情况,就会对应上面的结果。
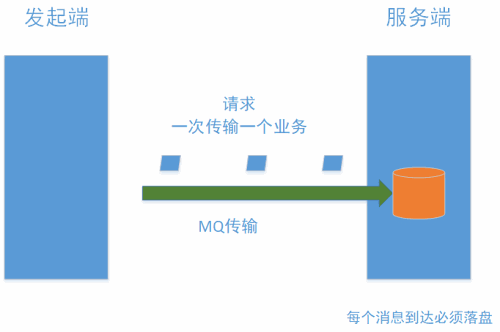
图1
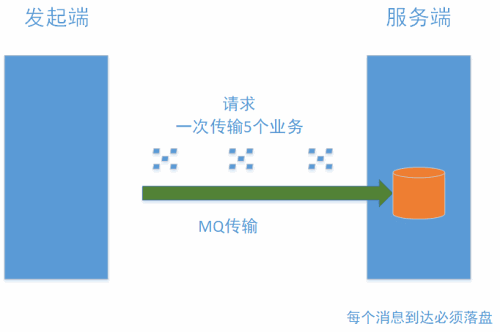
图2
注:MQ在“持久模式”下必须落盘
请求的频率相同,但数量不同(图1是一次请求携带一个报文,图2 是一次请求携带5个报文),对于接收端(即服务器)每次收到请求,都要落盘。如果一个请求只有一个报文,也要一个写IO,如果一个请求是5个报文,(报文size都很小,5个报文在一个block里)也要一个写IO。因此写IO的数量是一样,IOPS相同,util相同。
那么为什么会一个请求有时包含一个报文,有时包含多个报文呢?
我们向服务器发起业务是采用消息中间件MQ,MQ有一个参数是batchsz,即一个批次的传输最多传多少个报文。这个batchsz默认是50,也就是说MQ会最多凑齐50个报文一起发过去。
如果发起端发送的频率比较低,那么单位时间内,凑不齐50个报文,也许就一次一个的发送。如果吞吐量很大,单位时间内,可以凑出好多报文,也许一次10个、20个甚至50个报文一起发。N个报文在一个block中落盘,只有一次IO。
举例2
某系统需要写日志,日志在缓存(内存)中存放,假设缓存每秒钟定时刷入磁盘。如果每秒做1个业务则写1次日志刷一次磁盘,如果每秒做100个业务则写100次日志可能还是刷一次磁盘。
这种情况想,TPS涨了100倍,但对于日志模块的IOPS是一样的。
综上
util=100%并不意味着磁盘读写能力到了瓶颈(只代表单车道到了瓶颈,不代表别的车道不能走车),也并不意味着业务系统的TPS到了瓶颈,因为业务的吞吐量(单位时间请求数)和读写磁盘的IO并不是一一对应的关系。
但util仍然是重要的性能指标,能帮助我们发现潜在的性能问题。可以为未来可能的性能问题,提供排查线索。
比如在例1中,如果因为某些原因调整了MQ的batchsz参数(报文太大、网络不稳定等因素均可以触发客户的冲动去改这个参数),将batchsz设置为1,我们发现整个系统的极限吞吐量立刻从500 TPS下降到100 TPS以下。