这种方式,简单来说,就是一个外部请求进来后,让其在尽可能短的时间内处理完成。常见的方法有以下几种:
(1)提升调用链上各节点的处理速度
从技术角度考虑:在数据库层面,可以考虑加索引、读写分离、分库分表等;在应用层层面,可以考虑加缓存(本地缓存,分布式缓存,或两者叠加)、复杂查询走ES索引;在代码编写时,可以考虑更高效的算法和数据结构,比如:读多写少用数组、写多读少用链表、取余采用位运算等。
从业务角度考虑:尽量避免重复查询;对于一些查询类操作,尽可能采用批量查询;上游调用方尽可能使用更合适的下游接口,比如:下游服务方有分别返回A、B、AB的三类接口,如果上游使用方仅需要A信息,应使用A接口;如果同时需要AB信息,应使用AB接口,而不是依次调用A、B接口,再在内存中做聚合。
(2)请求内部做并行化处理
这种思想,就是将单个请求拆分为多个子请求,各子请求并行处理,最后对子请求结果合并后返回。在实践中,我们基于 CompletableFuture 实现了一套并行处理框架,并成功运用到了商品详情页加载场景中。
(3)请求处理异步化
此思想,最典型的方法是采用消息队列,比如:下单操作时,除了扣减库存、生成订单外,还会给用户发送支付成功消息、赠送积分等后置操作。对于这些非核心的后置流程,可以采用消息队列做异步化处理,以此提升下单接口的性能。其他一些方法还有:在进程内,另开一个线程执行这些非核心流程;或者先将非核心操作数据暂存在某种介质(DB表、redis等)中,然后采用定时任务定期扫描并执行这些操作。
2)并行处理多个请求
字面意思来看,就是当有多个外部请求进来时,可以让系统内部多个节点分别处理这些请求,或者节点内部做并行处理。比如:节点采用集群部署,并通过负载均衡策略,将用户请求分摊到不同的节点进行处理;节点内部采用线程池,通过另开线程来实现。
三、我们是怎么做的
在具体讲述之前,先带大家一起熟悉下当时的业务场景:用户首先访问直播商品详情页,然后购买此商品,紧接着再次访问详情页面时,会出现直播间入口,在进入直播间之前,会做一次权限校验,校验通过后,方才可以进入直播间与讲师进行互动。详细的流程可见图:
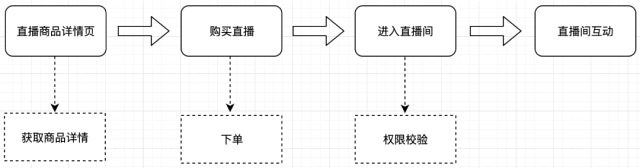
从上述流程中,可清晰看出,主要涉及到三种外部请求:查询直播商品详情;商品下单;进入直播间前做用户权限校验。当时通过流量监控数据以及日志分析发现,性能瓶颈主要在“直播商品详情加载”这一环节。
直播商详这块,主要是因为上游服务的请求量超过了下游服务能承受的吞吐量,导致大量RPC调用超时。具体反应的问题点有:
(1)依赖的部分非核心接口没有加缓存、做降级,导致整个请求失败;
(2)依赖的部分核心接口性能较差,导致后续请求一直被阻塞,直至超时异常返回;
(3)下游服务提供的查询接口比较重量级,但上游服务仅需要返参中的部分字段,导致单次查询RT一直下不去;
(4)上游调用方使用了错误的下游接口,比如上游调用方本来可以调用一次详细信息查询接口,便能获取所有需要的信息,可实际中,却先后调用了两种查信息的接口,才拿到完整的信息;
(5)无状态查询接口没有加缓存,导致了频繁的RPC调用。
针对上述这些问题点,我们当时主要从以下几点去做了优化:
优化前,我们重新梳理了整个调用链上,接口的强弱依赖关系,以及每个接口的RT情况
1) 针对弱依赖接口,从超时时间、缓存策略、降级策略三个层面进行了优化
- RPC调用超时时间设置策略
统计出弱依赖接口 TP99(RT较稳定的接口)/ TP95 (RT波动较大接口)的RT,设置它们的超时时间为 (1 + 50%) (TP99 或 TP95)
这里讲下为什么要这样设置超时时间:一般我们会设置超时时间为2s或3s,但每个接口的RT是不一样的,比如:接口A的RT稳定在100ms内,那么,如果超时时间是2s,假若接口A超时了,本次RT至少是2s,但如果超时时间设置为100ms,且我们加了1次重试,那么,本次请求的RT不会超过200ms,同时,重试时接口很大概率会正常返回结果。
- 缓存策略
给接口添加前置缓存。我们采用了公司自研的分布式缓存zanKV,缓存的更新策略是:采用了两个缓存,缓存A和缓存B(缓存A的失效时间为m分钟,缓存B为n分钟,且n>2m),首先从缓存A读数据,有则直接返回,没有则从B读数据,并在返回之前,异步启动一个更新线程,同时更新缓存A和缓存B。
- 降级策略
接口接入熔断降级机制,并对异常做捕获,返回默认值。
2)针对强依赖接口,从超时时间、重试策略、缓存策略三个层面做了优化
- RPC调用超时时间设置策略
统计出强依赖接口 TP99 的RT,设置它们的超时时间为 (1 + 50%) (TP99)
- 重试策略
根据接口RT波动性,基于dubbo的重试机制,设置重试次数为2或3次。
- 缓存策略
对于商品基础信息,考虑到“缓存预热”、“热点访问”等问题,接入了公司TMC(透明多级缓存),具体说明可见文档 https://mp.weixin.qq.com/s/BnWtbetNq076iRRZfnGRrw ;对于其他一些无状态查询信息,采用了本地缓存Guava。
3)商品详情信息聚合操作并行化
商品详情页面是一个聚合类信息展示窗口,它除了商品基础信息外,还包括A、B、C等内容(出于商业保密性,这里泛化内容名称),且这里的A、B、C和商品基础信息四者间是没有任何前后依赖关系的。当时我们将商品详情加载拆分为了4个子任务,并采用教育后端团队自研的并行处理框架,对子任务做了并行化处理,并聚合返回,较大提升了接口RT性能。
4)查询类接口能力收拢,下游服务方提供稳定的原子化接口
在问题点(3)、(4)中有提到,上游调用方使用了下游不太合适的接口。由于历史原因,当前下游服务方中有特别多的查询类接口,且很多查询类接口在功能上都是重叠的。本次我们针对查询类接口,按照其返参字段使用场景的不同,提供了三种不同粒度的通用类原子化接口,之后所有的查询类需求,都会强制要求上游调用方从这三类接口中选择。这三类接口如下:
- 粗粒度:返回最基本字段
- 中粒度:返回经常使用的字段
- 细粒度:返回详细信息
四、总结
产品功能是持续迭代的,性能优化也不是一蹴而就的事,大家在遇到性能问题时,可以参考本文提到的一些方法,做一些针对性的优化。同时,针对同一个节点,在不同的时刻,其优化点也可能不一样,比如:新功能刚上线时,查询性能的提升可能仅仅通过加索引的方式便能解决,但随着功能的不断叠加,后续的优化方向可能是“尽量走批量查询”、“加缓存”等方向。所以,性能优化还是要遵循“具体案例具体分析”这一基本原则。鉴于作者经验有限,我对性能优化的理解难免会有不足之处,欢迎大家共同探讨,共同提高。
源自公众号 有赞coder