if (value >= 1 && value <= 10) {
System.out.println("I have " + value + " cards." );
}
等价划分和边界测试在这里仍然有用:20 和 30 是同一类,-5 和 -10 是同一类;0、1、2、9、10、11 就是它们的边界。同样,对于黑盒测试,也可以应用覆盖率分析,这就涉及到接下来的内容:业务建模和图论。
3、业务建模
先来看一个常见场景:登录。按照最粗略的设计,它可能会是这个样子:
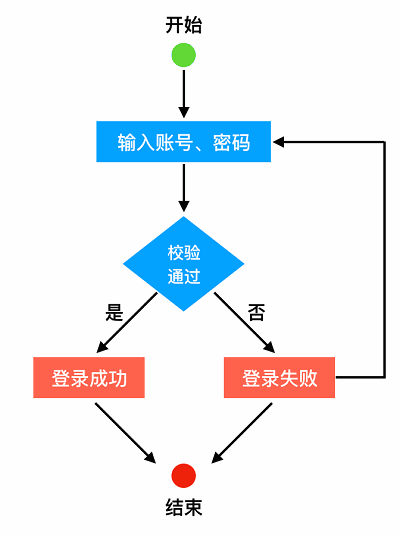
当然,在真实情况下往往不会这么简单,比如忘记密码需要重置、在多次错误输入的情况下账号会被锁定等等。所以我们把场景中的红色部分做进一步的拓展:
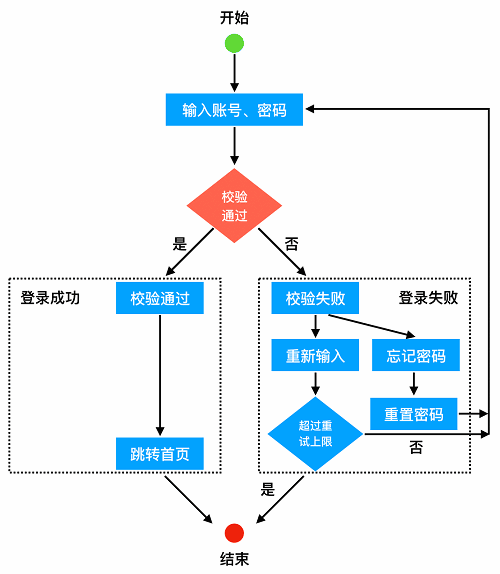
注意这里其实并没有往流程中注入更多的东西,只是把“登录成功”和“登录失败”这两个部分(见虚线框)做了展开描述。然后,假设“校验通过”这个判断步骤的代码如下:
if (uname == null || pwd == null) {
return errorResult("账号名或密码不能为空");
}
UserDO user = userMapper.getUserByName(uname);
if (user.getPwd.equals(encry(password))) {
return succResult("登录成功");
} else {
return errorResult("登录失败");
}
可以将它转化为等同的图形(因为篇幅的关系,登录成功和失败的细节重新被折叠):
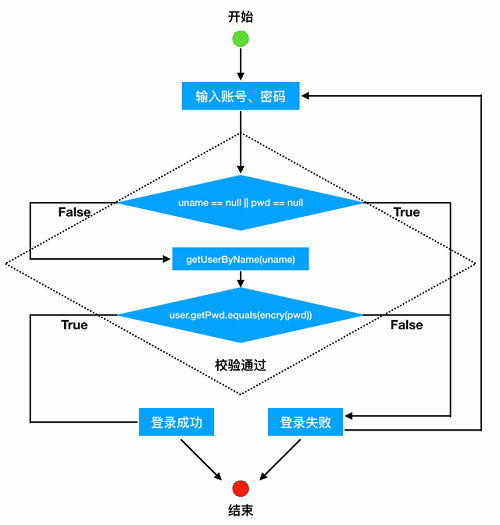
这个例子阐明了一件事情:为什么上篇文章里说,像等价划分、边界测试、覆盖率分析等常见的用例设计策略,不能说它只适用于黑盒或白盒,在绝大部分情况下(确实也存在少数特定方法),黑盒、灰盒、白盒只是分解程度上的不同,它们可以通用、甚至混用。比如上图就是将黑盒部分和白盒部分混合在一起。
整个业务系统,都可以按照这种方式进行不同程度的拆解。拆解的目的,是为了得到输入点、输出点以及它们之间的可能路径。所有输入点的可选项,就是输入域;所有输出点的可选项,就是输出域,而输入点到输出点之间走过的路径的重复度(覆盖率分析),就是等价划分的依据。因此,拆解的粒度越细,能够识别的(子)节点和(子)路径越多,获得的输入域和输出域也就越完整,进行的等价划分也就越精确。
这个拆解的过程,我们就叫做业务建模。它核心依赖两张图:业务流程图和数据流程图。以一个简化过的购物下单流程为例,两张图分别如下(因画图工具的限制,图形的样式不专业,但不影响对内容的说明):
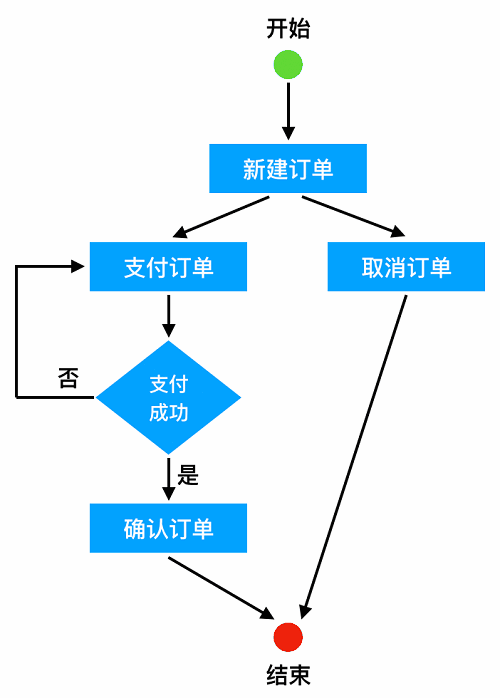
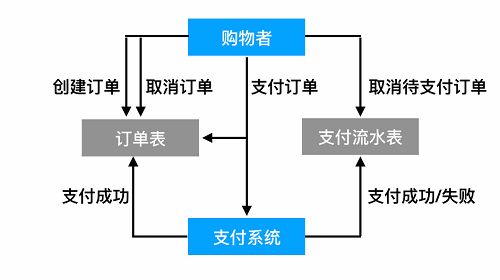
业务流程图比较好理解,即前面所说的路径,那为什么还需要一张数据流程图呢。原因是第一张流程图中存在隐蔽的“陷阱”:当我们新发起一个订单支付和支付失败需要重新支付时,虽然在流程图里的节点看起来是同一个,但实际上二者不是等价的(订单状态不一样,流水记录也不一样),所以“严谨”一点说,完整的流程图应该是这样:
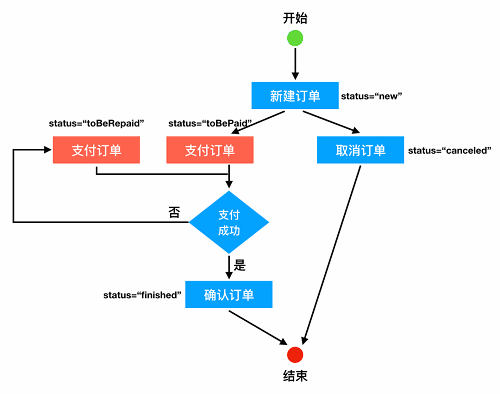
由此可以看出,数据流程图对测试人员来说,有比较重要的“校验意义”,它可以帮助我们确认每个步骤产生的结果的正确性和完整性。
此外,它还可以做为模块化测试的依据:我们可以从庞大、复杂的业务流中,选择一部分节点和路径,做为一个模块。只要保证输入点的所有数据状态一致,就可以认为每次测试都是“幂等”的,它所到达的输出点的数据状态也应该与预期一致。由此,将复杂的业务系统隔离成一个个小的子系统,降低整体测试的复杂度。
那么,我们又该如何确认测试的完整性?假设有一个逻辑复杂的业务模块,它的流程图(实线部分)如下:
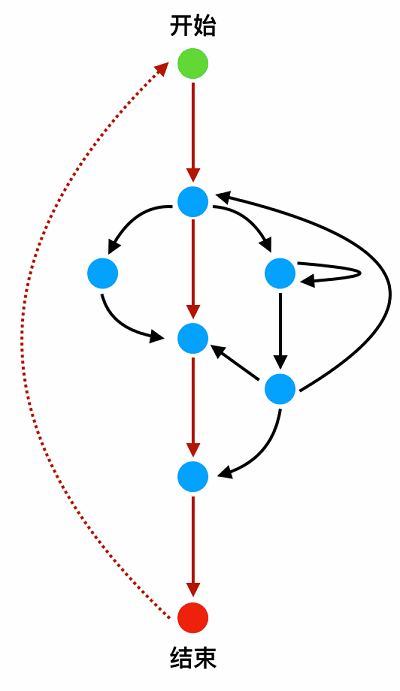
这时添加一条从结束点到开始点的路径(虚线部分),这张图就变成了一张有向环图(比如红色部分就是一个环)。从开始点到结束点的路径分支数,就等同于有向图的圈数。使用图论中的公式:V(G) = E - N + P(V 代表圈复杂度,E 代表边数,N 代表节点数,P 代表连通组件数(因为上图所有节点都是连通的,所以 P 为 1)),计算出圈数 = 13 - 8 + 1 = 6。即如果我们想要尝试所有的路径分支,至少需要 6 个测试用例,感兴趣的小伙伴可以自行数一数。在这张图中,边数最少的路径,我们一般将它做为关键路径(主路径),其他路径做为次要路径(辅路径)。边数越少,说明路径越重要,据此可以做为用例等级判断的依据。
更多测试相关的图论知识,推荐阅读机械工业出版社的《软件测试:一个软件工艺师的方法》(【美】保罗 C.乔根森(Paul C.Jorgensen) 著)。
4、其他一些测试法
除了以上讲解的“理性”的测试方法,还有一些“感性”的测试方法,同样可以给测试人员带来较大的帮助,最后我就选择部分常见的方法做个介绍。
角色分析法
角色分析法,是将自己作为目标用户来思考:如果我是用户,会以什么样的方式来使用产品。我们可以将用户划分为不同的角色,并构建出这些角色的使用场景,最终转化为测试用例。该方法的的作用是“以终为始”,跳出自身的视角限制,来发现用例设计中的盲点。
错误推断法
错误推断法,是根据测试人员的经验和直觉,列举出可能会出现问题的情况。我们可以在类似头脑风暴或用例评审的场合中,使用它来收集群体的想法。它非常依赖使用者的感觉,因此只能做为常规用例设计方法的补充,或在紧急的情况下采用,而不应将它做为主要的用例设计方法。
历史经验法
错误的发生往往会有一些“惯性”,所以在测试时,可以回顾一下过去在相同模块(或领域)发生过的问题,对它进行重复校验,也许会有“意外惊喜”。同样,当出现测试遗漏时,一定要及时补充我们的测试用例库,以免跌倒在同一个坑里。
现场验证法
测试人员设计出的用例通常是一种“测试数据”,我们很难确保它们能够覆盖到全部真实的数据情况。所以会采用一些方法来验证待发布产品在实际场景下的表现,比如预发测试、灰度测试、流量回放等等。
探索性测试
探索性测试严格上说不是一种测试技术,只是一种测试风格,它可以包含以上列出或未列出的各种测试方法。每次在探索性测试开始之前,可以定好这次测试的“主题”,或干脆就“自由发挥”,来增加发现深层缺陷的机会。这种方法如果结合众测,会有很好的效果。
5、结尾
测试用例设计是一个非常大的话题,以上这些内容还远远不能完整表达测试用例设计的精华,但由于时间的关系,暂时也不去做更多的展开讨论。随着测试理论和技术的发展,也许将来会出现更多、更智能的用例设计策略,就让我们“拭目以待”吧!
小虾米(2022-09-02 16:58:30)
学习到了,大神总结的很棒~