当前微服务架构下,每个服务都是至少2台服务器集群部署,一个功能可能需要大量的后端服务协作完成,大家是不是会遇到以下几个问题?
- 如何快速发现有问题的服务?
- 如何判断故障影响范围?
- 如何梳理服务间依赖关系?
- 如何分析链路性能问题?
- 对于一次慢请求,如何找到慢请求的来源?
其实上述问题,链路跟踪技术可以解决。

链路跟踪概述
“链路追踪”一词是在2010年提出的,当时谷歌发布了一篇Dapper论文,介绍了谷歌自研的分布式链路追踪的实现原理,还介绍了他们是怎么低成本实现对应用透明的。
其实Dapper一开始只是一个独立的调用链路追踪系统,后来逐渐演化成了监控平台,并且基于监控平台孕育出了很多工具,比如实时预警、过载保护、指标数据查询等。
除了谷歌的dapper,还有一些其他比较有名的产品,比如阿里的鹰眼、大众点评的CAT、Twitter的Zipkin以及国产开源的skywalking等
他们的优缺点如下图:
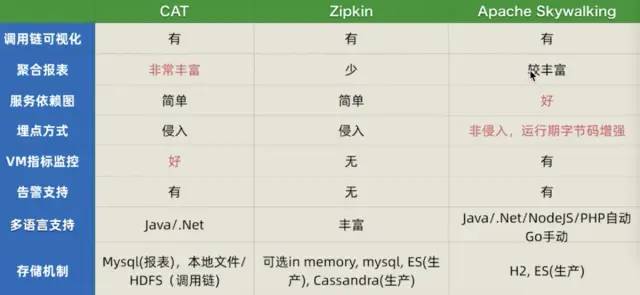
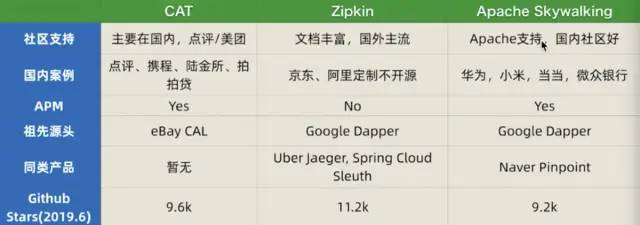

1、Zipkin欠缺APM报表能力,不建议;
2、企业生产级,推荐CAT,但是侵入性较强;
3、关注和试点SkyWalking,产品升级完善快,社区活跃,埋点无侵入也失去了一些灵活性;
4、用好调用链监控,需要自研能力。
本文就单独分享国产开源的skywalking,目前很多互联网项目都在使用
Skywalking原理探究
skywalking支持dubbo,SpringCloud,SpringBoot集成,代码无侵入,通信方式采用GRPC,性能较好,实现方式是java探针,支持告警,支持JVM监控,支持全局调用统计。
Skywalking架构是怎样的?
skywalking和zipkin一样,也分为服务端和客户端,服务端负责收集日志数据并且展示,架构如下:
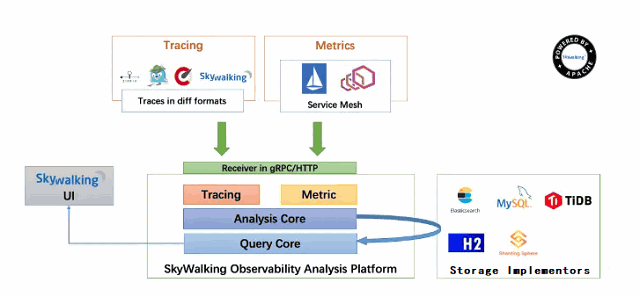
上述架构图中主要分为四个部分,如下:
- 上面的Agent:负责收集日志数据,并且传递给中间的OAP服务器
- 中间的OAP:负责接收 Agent 发送的 Tracing 和Metric的数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 左面的UI:负责提供web控制台,查看链路,查看各种指标,性能等等。
- 右面Storage:负责数据的存储,支持多种存储类型。
看了架构图之后,思路很清晰了,Agent负责收集日志传输数据,通过GRPC的方式传递给OAP进行分析并且存储到数据库中,最终通过UI界面将分析的统计报表、服务依赖、拓扑关系图展示出来。
字节码增强
字节码增强(bytecode-enhance)指的是在Java字节码生成之后,对其进行修改,从而增强其功能。
字节码增强有很多方式,例如编译期增强,直接使用ASM等工具修改字节码,或者运行期增强,例如使用Java Agent等技术。
目前很多互联网常见组件底层都是用的字节码增强技术,譬如jacoco、spring的aop等等, skywalking agent其实就是用的字节码增强技术。
后期有机会写篇文章单独分享这个技术。
Skywalking基本功能概述
1、浏览页面功能请求的后端链路
经常在页面做业务测试的小伙伴,会不会对后端服务链路有所好奇呢?
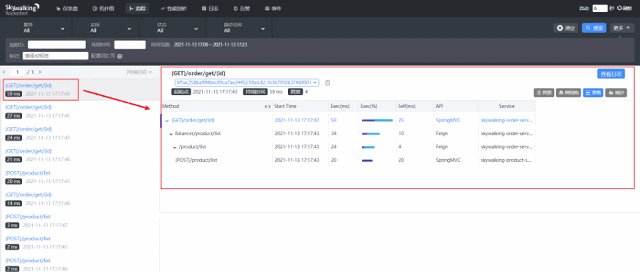
如上图,可以看到请求获取订单id的接口,涉及到的服务和每个服务接口执行的时间。既方便我们定位问题的发生范围,也方便我们压测过程中定位服务性能的瓶颈。
2、Global全局维度
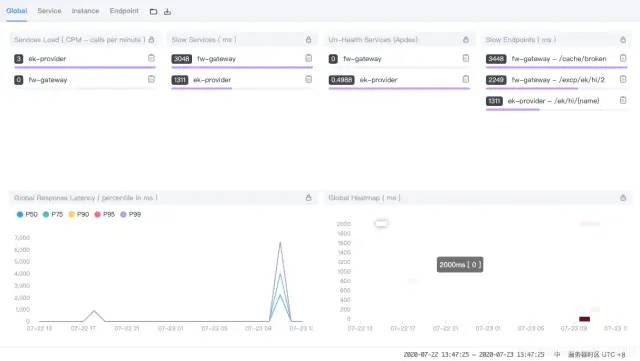
第一栏:Global、Server、Instance、Endpoint不同展示面板,可以调整内部内容
- Services load:服务每分钟请求数
- Slow Services:慢响应服务,单位ms
- Un-Health services(Apdex):Apdex性能指标,1为满分。
- Global Response Latency:百分比响应延时,不同百分比的延时时间,单位ms
- Global Heatmap:服务响应时间热力分布图,根据时间段内不同响应时间的数量显示颜色深度
底部栏:展示数据的时间区间,点击可以调整。
通过全局图,我们可以知道整个系统有哪些服务以及整个系统的负载现状。
3、Service服务维度
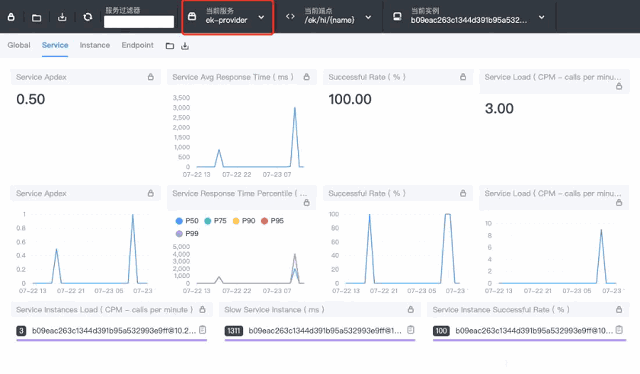
- Service Apdex(数字):当前服务的评分
- Service Apdex(折线图):不同时间的Apdex评分
- Successful Rate(数字):请求成功率
- Successful Rate(折线图):不同时间的请求成功率
- Servce Load(数字):每分钟请求数
- Servce Load(折线图):不同时间的每分钟请求数
- Service Avg Response Times:平均响应延时,单位ms
- Global Response Time Percentile:百分比响应延时
- Servce Instances Load:每个服务实例的每分钟请求数
- Show Service Instance:每个服务实例的最大延时
- Service Instance Successful Rate:每个服务实例的请求成功率
通过上图可以看到某个具体服务的负载情况,在性能瓶颈定位和调优过程中特别实用。